
Kafka分区
设置topic下的分区数
- 在 config/server.properties 配置文件中, 可以设置一个全局的分区数量, 这个分区数量的含义是: 每个主题下的分区数量, 默认为 1

也可以在创建主题的时候, 使用 --partitions 参数指定分区数量
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic my_topic --partitions 2 --replication-factor 1 |
3.查看已创建主题的分区数量:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my_topic |

生产者与分区
org.apache.kafka.clients.producer.internals.DefaultPartitioner
默认的分区策略是:
如果在发消息的时候指定了分区,则消息投递到指定的分区
如果没有指定分区,但是消息的key不为空,则基于key的哈希值来选择一个分区
如果既没有指定分区,且消息的key也是空,则用轮询的方式选择一个分区
消费者与分区
首先需要了解的是:
消费者是以组的名义订阅主题消息, 消费者组里边包含多个消费者实例.
主题下边包含多个分区
消费者实例与主题下分区的分配关系
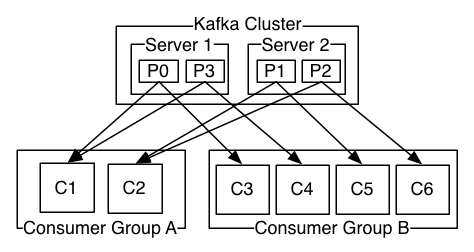
kafka 集群上有两个节点, 4 个分区
A组有 2 个消费者实例 (两个消费线程)
B组有 4 个消费者实例
由图可以看出, A组的消费者C1, C2 平均要消费两个分区的数据, 而 B 组的消费者平均消费 一 个分区的数据 ( 最理想的状态 ), 得到的结论是 : 一条消息只能被一个消费组中的一个消费者实例消费到, (换句话说, 不可能出现组中的两个消费者负责同一个分区, 同组内消费者不会重复消费 )
等等, 考虑的场景还不够, 下边再提些问题 :
如果分区数大于或等于组中的消费者实例数, 那就没有问题, 但是如果消费者实例的数量 > 主题下分区数量, 那么按照默认的策略 ( 之所以强调默认策略是因为可以自定义策略 ), 有一些消费者是多余的, 一直接不到消息而处于空闲状态.
但是假设有消费者实例就是不安分, 就造成了多个消费者负责同一个分区, 这样会造成什么 ? (重复消费就太可怕了)
我们知道,Kafka它在设计的时候就是要保证分区下消息的顺序,也就是说消息在一个分区中的顺序是怎样的,那么消费者在消费的时候看到的就是什么样的顺序,那么要做到这一点就首先要保证消息是由消费者主动拉取的(pull),其次还要保证一个分区只能由一个消费者负责。倘若,两个消费者负责同一个分区,那么就意味着两个消费者同时读取分区的消息,由于消费者自己可以控制读取消息的offset (偏移量),就有可能C1才读到2,而C2读到1,C1还没提交 offset,这时C2读到2了,相当于多线程读取同一个消息,会造成消息处理的重复,且不能保证消息的顺序,这就跟主动推送(push)无异。
消费者分区分配策略 (两种)
range策略是基于每个主题的,对于每个主题,我们以数字顺序排列可用分区,以字典顺序排列消费者。然后,将分区数量除以消费者总数,以确定分配给每个消费者的分区数量。如果没有平均划分(PS:除不尽),那么最初的几个消费者将有一个额外的分区。
简而言之:
range分配策略针对的是主题(也就是说,这里所说的分区指的某个主题的分区,消费者值的是订阅这个主题的消费者组中的消费者实例)
首先,将分区按数字顺序排行序,消费者按消费者名称的字典顺序排好序.
然后,用分区总数除以消费者总数。如果能够除尽,则皆大欢喜,平均分配;若除不尽,则位于排序前面的消费者将多负责一个分区.
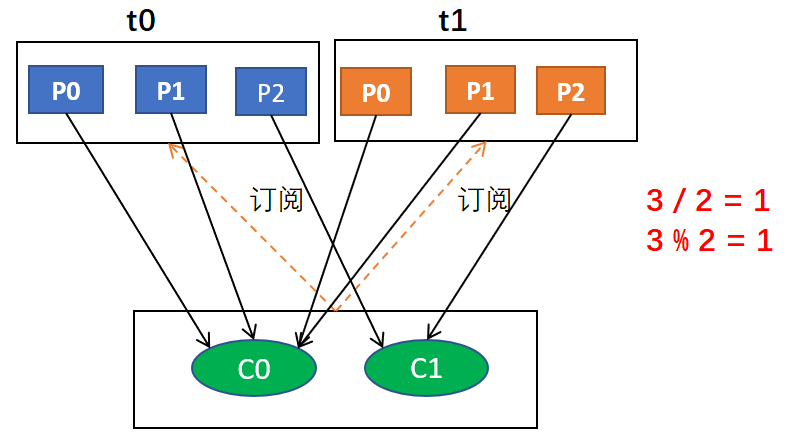
例如,假设有两个消费者C0和C1,两个主题t0和t1,并且每个主题有3个分区,分区的情况是这样的:t0p0,t0p1,t0p2,t1p0,t1p1,t1p2
那么,基于以上信息,最终消费者分配分区的情况是这样的:
C0: [t0p0, t0p1, t1p0, t1p1]
C1: [t0p2, t1p2]
因为,对于主题t0,分配的结果是C0负责P0和P1,C1负责P2;对于主题t2,也是如此,综合起来就是这个结果
上面的过程用图形表示的话大概是这样的 :
roundrobin (轮询)
roundronbin分配策略的具体实现是org.apache.kafka.clients.consumer.RoundRobinAssignor
轮询分配策略是基于所有可用的消费者和所有可用的分区的
与前面的range策略最大的不同就是它不再局限于某个主题
如果所有的消费者实例的订阅都是相同的,那么这样最好了,可用统一分配,均衡分配
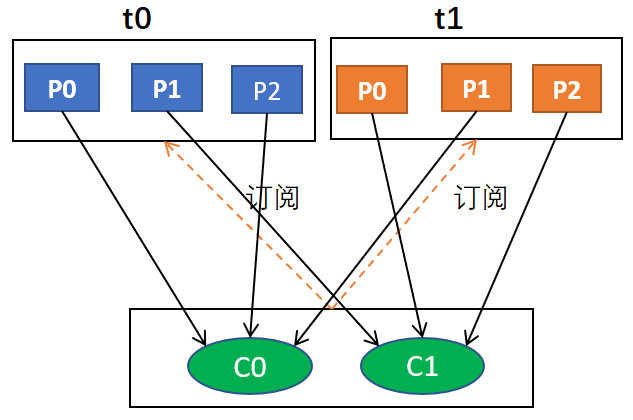
例如,假设有两个消费者C0和C1,两个主题t0和t1,每个主题有3个分区,分别是t0p0,t0p1,t0p2,t1p0,t1p1,t1p2
那么,最终分配的结果是这样的:
C0: [t0p0, t0p2, t1p1]
C1: [t0p1, t1p0, t1p2]
用图形表示大概是这样的:
 wechat
wechat alipay
alipay










