
孤立点分析
孤立点分析
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。主要研究计算机怎样模拟或实现人类的学习行为,以获取新的知识和技能,重新组织已有的知识结构,不断的改善自身的性能。
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。这些算法是一类能从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。简而言之,机器学习主要以数据为基础,通过大数据本身,运用计算机自我学习来寻找数据本身的规律,而这是机器学习与统计分析的基本区别。
机器学习主要有三种方式:监督学习,无监督学习与半监督学习。
(1)监督学习:从给定的训练数据集中学习出一个函数,当新的数据输入时,可以根据函数预测相应的结果。监督学习的训练集要求是包括输入和输出,也就是特征和目标。训练集中的目标是有标注的。如今机器学习已固有的监督学习算法有可以进行分类的,例如贝叶斯分类,SVM,ID3,C4.5 以及分类决策树,以及现在最火热的人工神经网络,例如BP神经网络,RBF神经网络,Hopfield神经网络、深度信念网络和卷积神经网络等。人工神经网络是模拟人大脑的思考方式来进行分析,在人工神经网络中有显层,隐层以及输出层,而每一层都会有神经元,神经元的状态或开启或关闭,这取决于大数据。同样监督机器学习算法也可以作回归,最常用便是逻辑回归。
(2)无监督学习:与有监督学习相比,无监督学习的训练集的类标号是未知的,并且要学习的类的个数或集合可能事先不知道。常见的无监督学习算法包括聚类和关联,例如K均值法、Apriori算法。
(3)半监督学习:介于监督学习和无监督学习之间,例如EM算法。
如今的机器学习领域主要的研究工作在三个方面进行:1)面向任务的研究,研究和分析改进一组预定任务的执行性能的学习系统;2)认知模型,研究人类学习过程并进行计算模拟;3)理论的分析,从理论的层面探索可能的算法和独立的应用领域算法。
算法描述
1.算法摘要
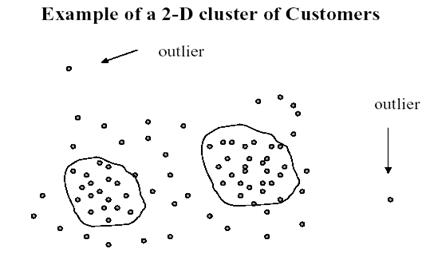
孤立点分析是数据挖掘中一个重要方面,用来发现“小的模式”(相对于聚类而言),即数据集中显著不同于其它数据的对象。孤立点又叫离群点。
Hawkins(1980)给出孤立点(outlier)的定义:孤立点是在数据集中与众不同的数据,使人怀疑这些数据并非随机孤立点,而是产生于完全不同的机制。孤立点可能在聚集运行或者检测的时候被发现,比如一个人的年龄是999,这在对数据库进行检测的时候就会被发现。还有就是outlier可能是本身就固有的,而不是一个错误,比如CEO的工资就比一般员工的工资高出很多。
2.算法原理
孤立点的挖掘方法主要有:基于统计学的、基于距离的、基于密度的局部离群点方法和基于深度偏差的方法。
马克威孤立点算法是基于距离的:设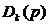 表示p点和它的第k个最近邻居的距离。直观地看,
表示p点和它的第k个最近邻居的距离。直观地看,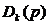 越大,p越有可能成为孤立点。
越大,p越有可能成为孤立点。
给定d维空间中包含N个点的数据集、参数N(孤立点个数)和k(偏差距离),如果满足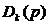 的点
的点![]() 不超过n-1个,那么称p为
不超过n-1个,那么称p为![]() 孤立点。
孤立点。
如果对所有数据点根据其距离进行从大到小排序,那么前n个点就被看作是孤立点。
算法步骤如下,对每个p点,计算它的第k个最近邻居的距离,把具有极大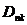 值的前个n点作为孤立点。该算法每次处理一个点p,就需要扫描一遍数据库,总共需要扫描N遍(N为数据点数)。
值的前个n点作为孤立点。该算法每次处理一个点p,就需要扫描一遍数据库,总共需要扫描N遍(N为数据点数)。
算法应用
孤立点分析被广泛地应用于各种行业,如电信和信用卡欺骗(如检查购买金额或购买次数异常等)、贷款审批、药物研究(如用于发现对多种治疗方式的不寻常的反应)、气象预报、金融领域(如检查洗钱等异常行为)、客户分类(如确定极低或极高收入的客户的消费行为)、网络入侵检测等。
相关应用
聚类分析、异常监测、异常欺诈、行为异常
优点和缺点
优点:应用领域广泛,对异常检测、极端情况的事件发生尤其有用。
缺点:孤立点分析时,有时候得到的结果并不是我们想要的,是数据本身固有的一种属性,如总经理的工资待遇比员工高很多;在时间序列中寻找孤立点时,难度比较大,因为时间序列的数据可能隐藏在趋势、季节性或者其他循环规则变化中。对非整型的数值型数据,孤立点定义及分析需要特殊考虑。
 wechat
wechat alipay
alipay




