#Create the connection object myconn = mysql.connector.connect(host = "localhost", user = "root",passwd = "google",database = "PythonDB")
#creating the cursor object cur = myconn.cursor()
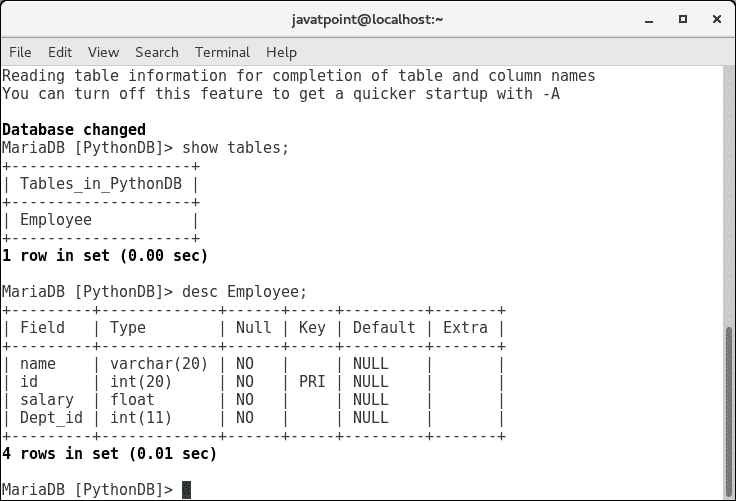
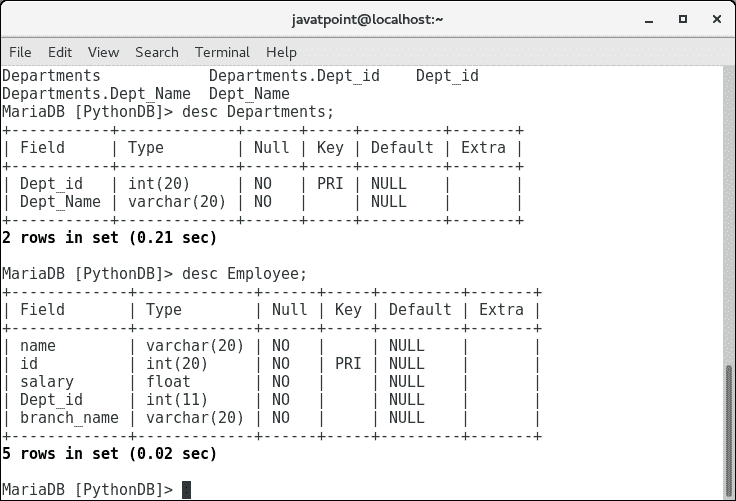
try: #Creating a table with name Employee having four columns i.e., name, id, salary, and department id dbs = cur.execute("create table Employee(name varchar(20) not null, id int(20) not null primary key, salary float not null, Dept_id int not null)") except: myconn.rollback()
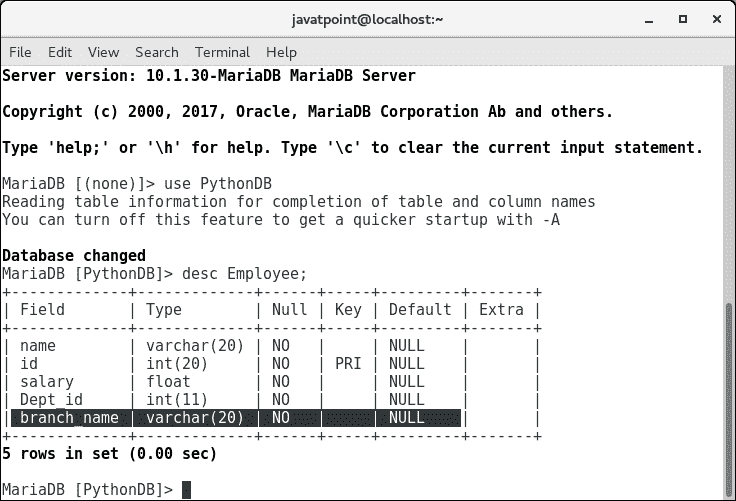
alter table Employee add branch_name varchar(20) not null
考虑下面的例子。
例子
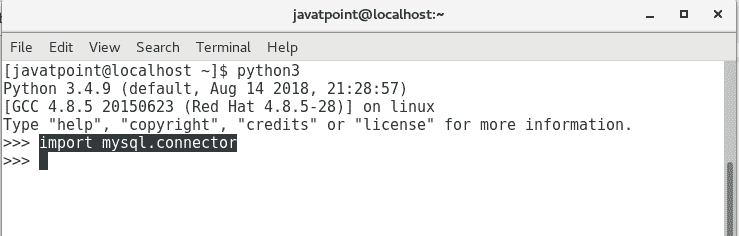
import mysql.connector
#Create the connection object myconn = mysql.connector.connect(host = "localhost", user = "root",passwd = "google",database = "PythonDB")
#creating the cursor object cur = myconn.cursor()
try: #adding a column branch name to the table Employee cur.execute("alter table Employee add branch_name varchar(20) not null") except: myconn.rollback()
myconn.close()
插入操作
向表中添加记录
INSERT INTO 语句用于向表中添加一条记录。在 python 中,我们可以用格式说明符(%s)代替值。
我们在游标的 execute()方法中以元组的形式提供实际值。
考虑下面的例子。
例子
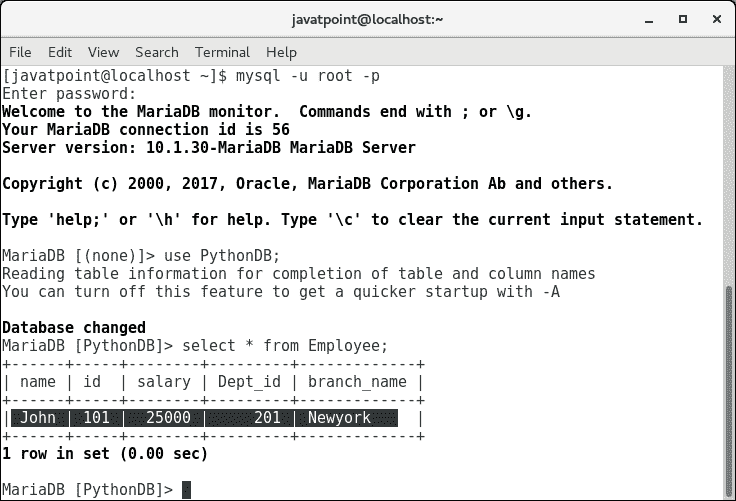
import mysql.connector #Create the connection object myconn = mysql.connector.connect(host = "localhost", user = "root",passwd = "google",database = "PythonDB") #creating the cursor object cur = myconn.cursor() sql = "insert into Employee(name, id, salary, dept_id, branch_name) values (%s, %s, %s, %s, %s)"
#The row values are provided in the form of tuple val = ("John", 110, 25000.00, 201, "Newyork")
try: #inserting the values into the table cur.execute(sql,val)
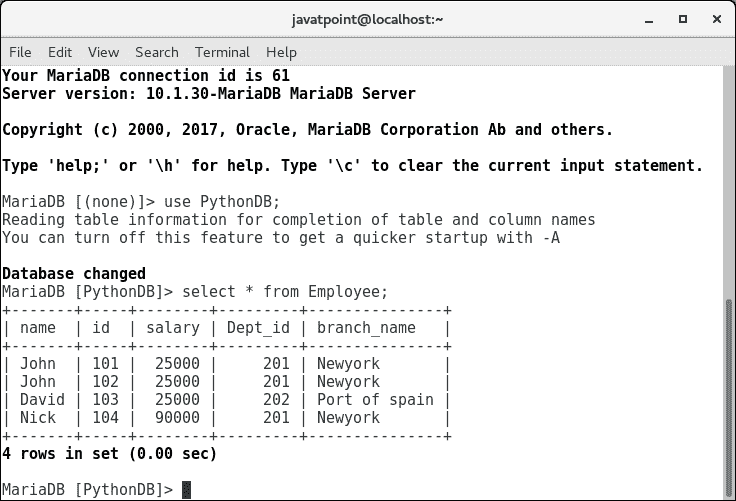
import mysql.connector #Create the connection object myconn = mysql.connector.connect(host = "localhost", user = "root",passwd = "google",database = "PythonDB") #creating the cursor object cur = myconn.cursor() try: #Reading the Employee data cur.execute("select name, id, salary from Employee")
#fetching the rows from the cursor object result = cur.fetchall() #printing the result for x in result: print(x); except: myconn.rollback() myconn.close()
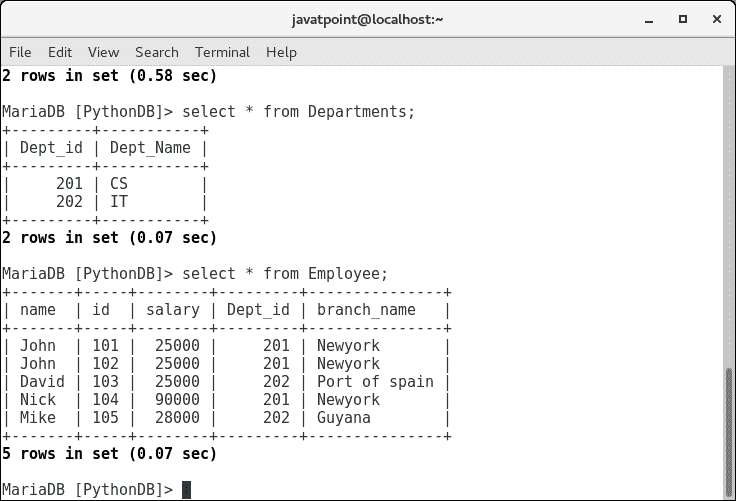
insert into Departments values (201, "CS"); insert into Departments values (202, "IT");
让我们看看每个表中插入的值。请看下图。
现在,让我们创建一个 python 脚本,将公共列(即 dept_id)上的两个表连接起来。
例子
import mysql.connector
#Create the connection object myconn = mysql.connector.connect(host = "localhost", user = "root",passwd = "google",database = "PythonDB")
#creating the cursor object cur = myconn.cursor()
try: #joining the two tables on departments_id cur.execute("select Employee.id, Employee.name, Employee.salary, Departments.Dept_id, Departments.Dept_Name from Departments join Employee on Departments.Dept_id = Employee.Dept_id") print("ID Name Salary Dept_Id Dept_Name") for row in cur: print("%d %s %d %d %s"%(row[0], row[1],row[2],row[3],row[4]))
except: myconn.rollback()
myconn.close()
输出:
ID Name Salary Dept_Id Dept_Name 101 John 25000201 CS 102 John 25000201 CS 103 David 25000202 IT 104 Nick 90000201 CS 105 Mike 28000202 IT
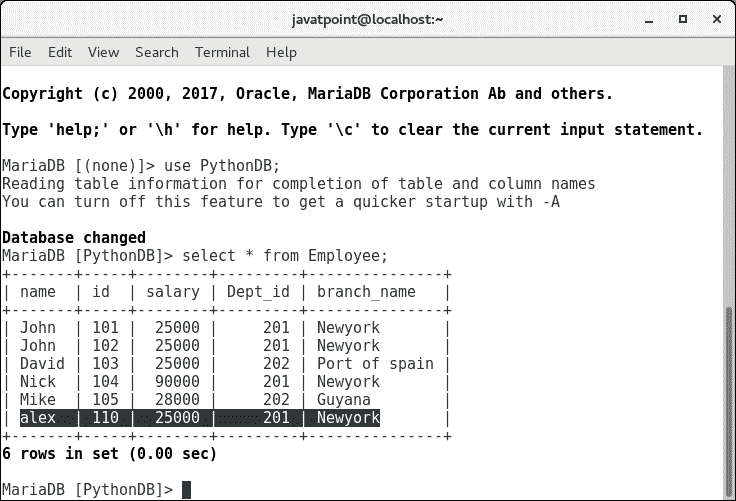
insert into Employee(name, id, salary, branch_name) values ("Alex",108,29900,"Mumbai");
这将插入一个不在任何部门工作的员工 Alex(部门 id 为空)。
现在,我们在“员工”表中有一名员工,其部门 id 不在“部门”表中。现在让我们在两个表上执行正确的连接。
例子
import mysql.connector
#Create the connection object myconn = mysql.connector.connect(host = "localhost", user = "root",passwd = "google",database = "PythonDB")
#creating the cursor object cur = myconn.cursor()
try: #joining the two tables on departments_id result = cur.execute("select Employee.id, Employee.name, Employee.salary, Departments.Dept_id, Departments.Dept_Name from Departments right join Employee on Departments.Dept_id = Employee.Dept_id")
print("ID Name Salary Dept_Id Dept_Name")
for row in cur: print(row[0]," ", row[1]," ",row[2]," ",row[3]," ",row[4])
except: myconn.rollback()
myconn.close()
输出:
ID Name Salary Dept_Id Dept_Name 101 John 25000.0201 CS 102 John 25000.0201 CS 103 David 25000.0202 IT 104 Nick 90000.0201 CS 105 Mike 28000.0202 IT 108 Alex 29900.0NoneNone
左连接
左连接包含左侧表中的所有数据。它对右连接的效果正好相反。考虑下面的例子。
例子
import mysql.connector
#Create the connection object myconn = mysql.connector.connect(host = "localhost", user = "root",passwd = "google",database = "PythonDB")
#creating the cursor object cur = myconn.cursor()
try: #joining the two tables on departments_id result = cur.execute("select Employee.id, Employee.name, Employee.salary, Departments.Dept_id, Departments.Dept_Name from Departments left join Employee on Departments.Dept_id = Employee.Dept_id") print("ID Name Salary Dept_Id Dept_Name") for row in cur: print(row[0]," ", row[1]," ",row[2]," ",row[3]," ",row[4])
except: myconn.rollback()
myconn.close()
输出:
ID Name Salary Dept_Id Dept_Name 101 John 25000.0201 CS 102 John 25000.0201 CS 103 David 25000.0202 IT 104 Nick 90000.0201 CS 105 Mike 28000.0202 IT

 wechat
wechat alipay
alipay









