
深入解读 MongoDB CDC 的设计与实现
MongoDB CDC 概述
MongoDB 是当下流行的一个基于文档的非关系性数据库。MongoDB CDC [1] 是 Flink CDC 社区 [2] 提供的一个用于捕获变更数据(Change Data Capturing)的 Flink 连接器,可连接到 MongoDB 数据库和集合,并捕获其中的文档增加、更新、替换、删除等变更操作,生成标准的 Flink Changelog 事件流,支持通过 Flink SQL 或 DataStream API 进行数据加工, 加工之后可以方便地写入到 Flink 所支持的各种下游系统中。
MongoDB CDC 核心功能
全增量一体化读取
在实际的业务场景中,常常需要同时采集 MongoDB 数据库中的存量数据以及增量数据。MongoDB CDC 能够一体化地读取全量数据和增量数据。在启动选项配置为 initial 模式时,CDC 会首先对目标集合进行扫描,并对现存的每一条数据各发送一条 Insert 记录;快照完成后,CDC 会自动转换为增量模式,开始捕获连接器启动后到来的变更数据。期间支持在任意时刻的故障恢复,且保证提供不丢不重的精确一次(Exactly-Once)语义。
支持多种消费模式
针对不同的场景需求,MongoDB CDC 可以设定为从以下模式中启动:
latest 模式在此模式下,MongoDB CDC 不会处理启动前已经存在的数据,只针对启动后到来的变更数据产生变更记录。这意味着连接器只能读取在连接器启动之后的数据更改。
initial 模式在此模式下,MongoDB CDC 会先对全部存量数据进行快照,待快照完成后再开始捕获变更数据。
timestamp 模式在此模式下,MongoDB CDC 会捕获给定的时间戳之后发生的变更数据。时间戳的取值必须在 MongoDB 的有效日志记录范围内。
支持产生完整变更事件流
MongoDB 6.0 之前的版本默认不会提供变更前文档及被删除文档的数据;利用这些信息只能实现 Upsert 语义(即缺失了 Update Before 数据条目)。但在 Flink 中许多有用的算子操作都依赖完整的 Insert、Update Before、Update After、Delete 变更流。如果需要补充缺失的变更前事件,一个自然的思路是在 Flink 状态中缓存所有文档的当前版本快照;在遇到被更新或删除的文档时,查表即可得知变更前的状态。然而在最坏的情况下,这种操作可能需要保存相当于 100% 原始数据量的记录
目前,Flink SQL Planner 会自动为 Upsert 类型的 Source 生成一个 ChangelogNormalize 节点,并按照上述操作将其转换为完整的变更流;代价则是该算子节点需要存储体积巨大的 State 数据。
MongoDB 6.0 的 Pre- and Post-Image 新功能 [6] 提供了一个更高效的解决方案:只要启用 changeStreamPreAndPostImages 功能,MongoDB 就会在每次变更发生时,在一个特殊的集合中记录文档变更前后的完整状态。MongoDB CDC 支持读取这些记录并产生完整事件流,从而消除了对 ChangelogNormalize 节点的依赖。
基于心跳的标记推动机制
目前版本的 CDC 实现需要全局唯一的回溯标记(Resume Token)来定位变更流的位置。然而 MongoDB 并不会无限地存储所有的日志,较早的变更记录可能会在保存时间超限或日志大小超限时被清除。
对于变更频繁的集合,清除记录并不会带来什么问题,因为每次获取最新的变更条目时都会一并刷新回溯标记,始终保证回溯标记的有效性。但对于一些变更非常缓慢的集合,可能出现“上一次变更非常久远,导致其对应的回溯标记已经被清除了”的情况,这意味着无法再从流中进行恢复并读取下一次变更(由于回溯标记不存在而无法定位)。
MongoDB 提供了解决这一问题的“心跳机制”选项,在流中没有变更数据时,也可以通过发送心跳包以刷新回溯标记。这样对于变更缓慢的集合也能保持其回溯标记更新,而不至于过期。可以通过 MongoDB CDC 的 heartbeat.interval.ms 选项来启用心跳机制。
MongoDB CDC 的设计方案
根据使用的技术方法不同,MongoDB CDC 的技术演进过程大致分为三个阶段:最早的 CDC(如早期的 Debezium MongoDB 等)基于查询 OpLog 日志集合实现,主要面向 MongoDB 的早期版本;第二阶段升级到了基于 MongoDB 3.6 提供的 Change Stream API 设计;在第三阶段,也就是最新的版本中,Flink CDC 社区实现了基于 FLIP-27 和增量快照算法的设计。
第一阶段:基于 OpLog 的设计方案
早期的 MongoDB 没有为变化监测的需求设置特别的 API。但为了支持主—副节点分布式部署情况下的数据同步和故障恢复,MongoDB 会将数据库中的所有文档操作记录写入一个特殊的系统集合 sys.oplog [3]。每条记录的格式如下:
|
其中 ts 段用于记录操作发生的唯一时间戳(第一位为 Unix epoch 时间戳,第二位为这一秒内的版本号) ;ns 记录了操作的数据库和集合、op 是进行的操作(例如 i代表插入)、o 是被插入的文档。连接器只需持续查询 OpLog 集合,即可获取时间顺序的最新数据,并产生对应的日志流。
需要留意的是,MongoDB 出于日志记录开销的考量,只会记录更新操作发生变化的字段;删除操作中只包含被删除文档的 _id 字段。因此这类基于 OpLog 的 CDC 实现需要额外的操作(例如,在 Update 后查询完整文档信息)才能产生 Flink Upsert(包括 Insert、Update After、Delete)事件流。由于 OpLog 并不记录更新前及删除前的文档数据,这类 CDC 通常不能产生 Update Before 事件。
除此之外,MongoDB 数据库的每个分片都有自己的 OpLog 集合,因此连接器需要同时和每个分片建立连接并处理同步问题,实现较为繁琐。
第二阶段:基于 Change Stream API 设计方案
MongoDB 3.6 引入了新的 Change Stream (变更流)API [4],支持数据库、集合层面的变更信息订阅,并提供了基于 Resume Token 的断点续传机制。例如,使用 db.<collection_name>.watch(),就可以订阅对应集合的操作变更,返回的每条变更记录数据的格式如下:
{ |
相比于读取 Oplog 的方式,基于变更流 API 的 CDC 具有这些优势:
对分片集群支持更好。要订阅分片集合的全部变更操作,也只需要建立一个变更流游标;
方便进行恢复。只需要记录每条记录的 Resume Token,即可在有效期限内任意回溯;
支持自动获取变更后完整文档。可以通过参数配置获取包含更新后完整文档的变更记录。
早期版本的 MongoDB CDC 就通过变更流 API 实现了流式更新的订阅。
第三阶段:基于增量快照算法的设计方案
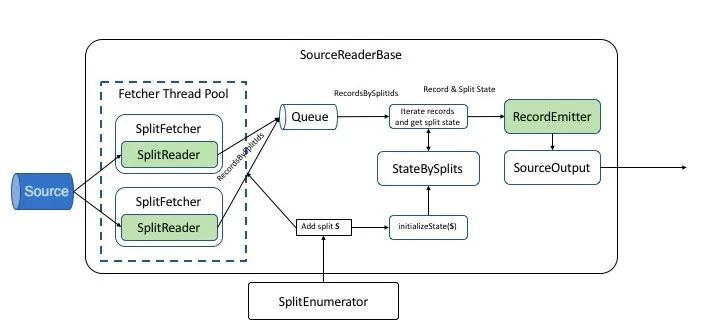
CDC 的变更监测操作通常分为两步:第一步是在启动时对当前数据库中的状态进行完整快照(Snapshot),第二步是监控实时的流式数据变更。早期版本的快照阶段为单并发读取,且不支持 Checkpoint 与故障恢复。这意味着在数据量很大时,快照阶段执行将花费相当长的时间,且一旦失败必须从头开始。FLIP-27 提案 [5] 给出了下一代 Flink Source 架构,将从源读取数据的职责抽象为两个模块,如下图所示:
SplitEnumerator,负责管理并将数据源拆分为多个抽象分片;
Reader,负责从抽象分片中读取实际的数据。
运行时,读取数据的过程也分为两个步骤:
一开始,执行 SplitEnumerator,将全部数据拆分成抽象分片;
将每个抽象分片分配给 Reader,并执行实际的读取逻辑。
Enumerator 和每个 Reader 各有自己的 Checkpoints,均支持故障恢复。各 Source 也无需自己维护分片、并发模型问题。
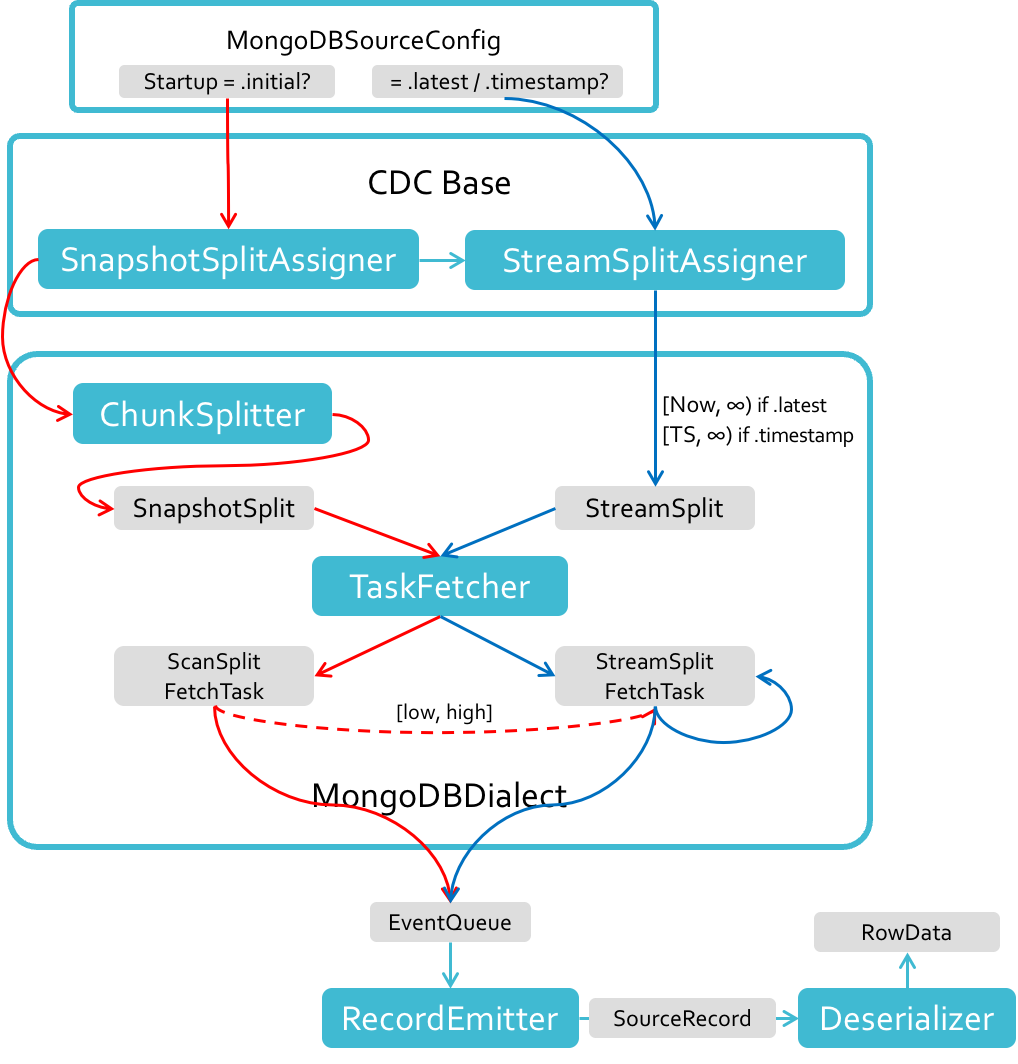
MongoDB CDC 在 Flink CDC 2.3 版本开始迁移到这一新的 Source 架构。在进行快照时,MongoDB CDC 需要将待快照的集合按 Key 进行拆分,策略如下:如果目标集合为分片集合,则按照实际的物理分片进行拆分;否则,使用 MongoDB 提供的 splitVector 函数均匀分片;如果无法调用 splitVector 则使用启发式算法,抽样估计文档的平均大小,并按数据行数进行拆分。
得到的每个分片都对应一个 MinKey 和 MaxKey 指定的文档范围,称作快照分片(SnapshotSplit)。
而在流式读取阶段,我们只需要指定数据流的起止时间点,确定要监控的流数据记录范围即可。这样的分片称为流式分片(StreamSplit)。如果将停止时间点设定为 MAX_TIMESTAMP(可表示的最大时间戳),则代表这是一个不限定停止时间点的无界流分片。
目前,启用了增量快照功能的 MongoDB CDC 使用 FLIP-27 推荐的 Source 接口定义方式 SplitEnumerator 会首先拆分存量数据,产生快照分片;在监测到全部的快照分片均完成之后,才会继续产生流式分片,转为流式读取。
TaskFetcher 在收到待处理的分片后,就会按照其类型(快照或流式)将其传递给对应的 SplitFetchTask 进行实际的读取工作。ScanSplitFetchTask 会根据传入的快照分片界定的 Key 范围从 MongoDB 数据库中读取存量数据;StreamSplitFetchTask 则会订阅 Change Stream API 来获取变更数据。
所有 SplitFetchTask 产生的记录都会被放入事件队列中,并由 RecordEmitter 转发给指定的反序列化器;反序列化器将其转化为最终的 RowData,交给下游消费。
出于兼容性考虑,使用传统 SourceFunction 定义的 MongoDB Source 仍然存在于目前版本的 MongoDB CDC 中,用于非增量快照模式。但这种定义方式已被 Flink 标记为不推荐的(Deprecated)用法,且将来可能会被删除。
MongoDB CDC 的底层实现
目前版本的 Mongo CDC 实现大量依赖 MongoDB 底层为变化数据的捕获提供的支持,如变更流 API、分片集合支持、变更前后快照等功能。下面详细介绍这些功能的底层机制,对底层原理不感兴趣的读者可以快速跳过本章节。
基于 Change Stream API 的 CDC 技术
上文提到,基于变更流 API 捕获变更数据相比于读取 OpLog 的实现更简单有效。然而实际上 MongoDB 的变更流 API 底层也是基于 OpLog 实现的,是在 OpLog 上提供的一层封装。它们存在以下的对应关系:
变更流中的每条记录都有着唯一的 _id(即 Resume Token),对应 OpLog 集合中的一次操作日志;
变更流中的 namespace、updateDescription、operationType 等字段和 OpLog 中记录的内容一一对应。
在此基础上,变更流 API 提供了以下便利:
支持通过任意有效的 Resume Token 回溯变更流由于通过 Resume Token(即 OpLog 记录的_id 字段)可以查找出 OpLog 中对应的操作记录,从而自对应位点开始消费接下来的变更数据。
支持从特定的 Timestamp 开始回溯变更流
MongoDB 提供了 startAtOperationTime 选项开启变更流,支持从给定的时间戳处开始读取变化。由于 OpLog 集合中包含了所有变更的时间戳,且按照时间有序排列,所以只需进行二分查找即可定位到给定时间戳对应变更流中的位置。
目前的 MongoDB 实现有个特殊的限制:如果指定的 Timestamp 发生在过去(即需要在 OpLog 中查找变更的起始点),则需要保证这一 Timestamp 在 OpLog 记录的日志范围内。这一限定很好理解:如果给定的时间戳在未来,则无需进行二分查找,只需等待该时间戳之后的变更数据到来再开始捕获即可;但如果给定的时间戳在过去,则只能在 OpLog 记录的范围内才能进行可靠的二分查找;如果该时间戳比当前 OpLog 最早的数据还要早,则 MongoDB 无法确定在它们之间是否有其他变更;即使有,也无法从该处恢复了,因为这些变更对应的 OpLog 日志已经被清除了。MongoDB 在遇到这种情况时会拒绝回溯。
支持 Full Document Lookup 功能
OpLog 为了节约存储开销,只会存储最少必要的变更数据。例如,对于一次更新操作,MongoDB 并不会将变更后完整的文档记录下来,而是只存储那些发生了变化的字段;即 OpLog 里面的更新操作日志中记录的不是完整的文档,不是很实用。如果需要完整的文档信息,还需要对 OpLog 中每条更新记录手动查找一次。
变更流 API 则将这一查询需求进行了包装:只需使用 fullDocument: updateLookup参数,MongoDB 就会在读取到 Update 事件时,在返回的记录中补充完整的文档,并记录在 fullDocument 字段中。注意这仅适用于 Update 类型的操作,因为 Insert 操作总是包含完整文档信息(因为插入操作前该文档还不存在);Delete 操作总是只包含 _id 信息(因为已被删除的文档无法再查找)。
需要注意的是,MongoDB 不保证 updateLookup 给出的文档一定与该更新操作的结果对应。也就是说,连续对同一文档进行 Update 操作产生的变更流记录,较早变更查出的 FullDocument 可能被较晚变更的内容覆盖。
这和手工读取 OpLog、再手动读取 Full Document 的问题是一样的。不过由于 MongoDB 的每个文档都具有唯一的 _id 字段,因此在 Upsert 模式的数据流中这一问题不会对结果产生太大影响。
MongoDB 分片集合的支持
MongoDB 的每个分片节点都具有自己的 OpLog 集合,分别记录属于自己分片的变更数据;这意味着如果需要基于 OpLog 监控分片集合的变更,则需要并行地监控每个分片的 OpLog 集合,并手动处理同步问题、按照时间戳对来自不同分片的变更日志进行排序并输出,难度和风险都比较高。
而变更流 API 对分片集合的变更捕获进行了封装,使其更加易用。即使通过变更流 API 订阅的是分片存储的集合,也只会产生唯一一个变更流游标,其中包含了来自所有分片的变更数据;且提供了很强的有序性保证,即产生的变更数据总是时间有序的。
MongoDB 的实现方式是给分片集合设计一个中心化的管理节点,负责从各个节点获取记录并排序,从而产生有序的输出。每个节点内部的 OpLog 记录总是有序的。那么在所有节点都给出一条该节点内最早的记录之后,其中最早的那一个就可以认为是全局最早值,可以发送给订阅 Change Stream 的客户端了。
但是这样其实会有问题:如果其中有个节点的数据始终没有被更新,那么它就不会给出变更记录;这样,中心节点就无法确认这个节点到底是很久以前有更新,只是一直没发出来记录,还是确实没有数据;这样就无法推进全局时间戳了。
MongoDB 对这一问题的解决方案和 Flink 的 Watermark 机制很类似:MongoDB 要求每个节点即使没有变更数据,也需要定期向中心节点发送一条空白指令。这样中心节点就可以确认每个节点的同步状态,从而推进全局时间戳。
高效地支持变更前后快照
Change Stream 底层是基于 OpLog 实现的,而 OpLog 不记录更新和删除前的文档信息。为了支持“获取变更/删除前文档”这一需求,MongoDB 不得不额外在某个位置保存这一信息。出于兼容性的考量以及储存开销原因,MongoDB 没有选择修改 OpLog 格式来储存额外字段,而是在特殊的集合中存储变更前后的文档信息(称为 Pre- and Post-Images),并提供了集合粒度的开关控制。
由于针对每次变更和删除操作都记录下前后快照的开销并不小,所以 MongoDB 提供了许多开关防止状态膨胀,例如:
支持在系统层面配置变更前后快照的过期时间:
|
支持对每个集合单独配置变更前后快照开启与否:
|
支持对每个变更流游标选择是否读取变更前后快照:
|
为什么要同时存储变更后的文档呢?之前提到的将 FullDocument 设定为 updateLookup 的方法,虽然可以得到变更后的完整文档信息,但却不能保证得到的一定是这一次更新之后的文档信息。例如,在连续进行两次更新操作时,可能会出现前一次更新操作的 FullDocument 被后一次覆盖的情况。究其原因,是因为这一信息是事后独立查询(Lookup)的,而非和变更事件本身相关联。
而变更后文档记录是在每次变更触发器中存储的,和特定的 OpLog 变更条目相关联,因此可以保证记录的文档反映了该变更的结果;将 fullDocument 选项设定为 required 或 whenAvailable 时,即可要求从变更后快照中读取记录,而非进行“事后查询”。
在启用 scan.full-changelog 选项时,MongoDB CDC 会要求从变更后文档记录中产生 Update After 事件,从而确保每条 Update After 事件与实际变更操作一一对应。这是通过 ChangelogNormalize 算子将 Upsert 流正规化的实现方式无法保证的。
参考
[1] MongoDB CDC 社区文档:
https://ververica.github.io/flink-cdc-connectors/release-2.4/content/connectors/mongodb-cdc(ZH).html
[2] Flink CDC 社区官网:
https://ververica.github.io/flink-cdc-connectors/
[3] MongoDB Oplog 文档:
https://www.mongodb.com/docs/manual/core/replica-set-oplog/
[4] MongoDB 变更流文档:
https://www.mongodb.com/docs/manual/changeStreams/
[5] Apache Flink FLIP-27 提案:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-27%3A+Refactor+Source+Interface
[6] MongoDB PreImages 文档:
https://www.mongodb.com/docs/atlas/app-services/mongodb/preimages/
[7] 阿里云 MongoDB CDC 文档:
https://help.aliyun.com/zh/flink/developer-reference/mongodb-cdc-connector
[8] 阿里云 Flink 实时计算 Release Notes:
https://help.aliyun.com/zh/flink/product-overview/august-21-2023
 wechat
wechat alipay
alipay





{kind=link}
{kind=link}
{kind=link}