
人工智能中的搜索算法
人工智能中的搜索算法
搜索算法是人工智能最重要的领域之一。本主题将解释人工智能中的所有搜索算法。
解决问题的代理:
在人工智能中,搜索技术是解决问题的通用方法。AI 中的理性智能体或问题解决智能体大多使用这些搜索策略或算法来解决特定问题并提供最佳结果。问题解决代理是基于目标的代理,使用原子表示。在这个主题中,我们将学习各种解决问题的搜索算法。
搜索算法术语:
搜索: 搜索是在给定的搜索空间中解决搜索问题的一个逐步过程。搜索问题可能有三个主要因素:
- 搜索空间: 搜索空间代表一组可能的解决方案,一个系统可能有。
- 开始状态: 是代理开始搜索的状态。
- 目标测试: 是观察当前状态,返回目标状态是否达到的功能。
搜索树: 搜索问题的树表示称为搜索树。搜索树的根是对应于初始状态的根节点。
动作: 它向代理提供所有可用动作的描述。
过渡模型: 每个动作做什么的描述,可以表示为一个过渡模型。
路径成本: 是给每个路径分配一个数值成本的函数。
解: 是从开始节点通向目标节点的动作序列。
最优解: 如果一个解在所有解中成本最低。
搜索算法的属性:
以下是搜索算法的四个基本属性,用于比较这些算法的效率:
完备性: 如果对于任意随机输入,至少有一个解存在,则保证返回一个解,则称搜索算法完备。
最优性: 如果为一个算法找到的解保证是所有其他解中的最优解(最低路径成本),那么这样的解被称为最优解。
时间复杂度: 时间复杂度是算法完成任务的时间度量。
空间复杂度: 是搜索过程中任意一点所需的最大存储空间,作为问题的复杂度。
搜索算法的类型
基于搜索问题,我们可以将搜索算法分为无信息(盲搜索)搜索和有信息搜索(启发式搜索)算法。
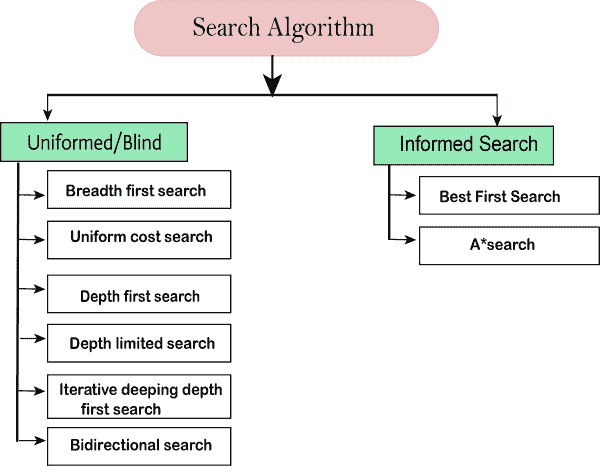
不知情/盲目搜索:
不知情的搜索不包含任何领域知识,如接近度、目标位置。它以一种蛮力的方式运行,因为它只包含关于如何遍历树以及如何识别叶节点和目标节点的信息。无信息搜索应用了一种搜索树的方式,不需要任何关于搜索空间的信息,如初始状态算子和目标测试,因此也称为盲搜索。它检查树的每个节点,直到它达到目标节点。
主要分为五种类型:
广度优先搜索
统一成本搜索
深度优先搜索
迭代深化深度优先搜索
双向搜索
广度优先搜索:
广度优先搜索是遍历树或图时最常用的搜索策略。这种算法在树或图中横向搜索,因此称为广度优先搜索。
BFS 算法从树的根节点开始搜索,并在移动到下一级节点之前展开当前级的所有后续节点。
广度优先搜索算法是通用图搜索算法的一个例子。
使用先进先出队列数据结构实现广度优先搜索。
优势:
如果有任何解决办法,BFS 将提供一个解决办法。
如果给定问题有多个解决方案,那么 BFS 将提供需要最少步骤的最小解决方案。
缺点:
它需要大量内存,因为树的每一级都必须保存到内存中才能扩展到下一级。
如果解决方案远离根节点,BFS 需要大量时间。
示例:
在下面的树结构中,我们展示了使用 BFS 算法从根节点 S 到目标节点 k 的树遍历。BFS 搜索算法分层遍历,因此它将遵循虚线箭头所示的路径,遍历的路径将是:
|
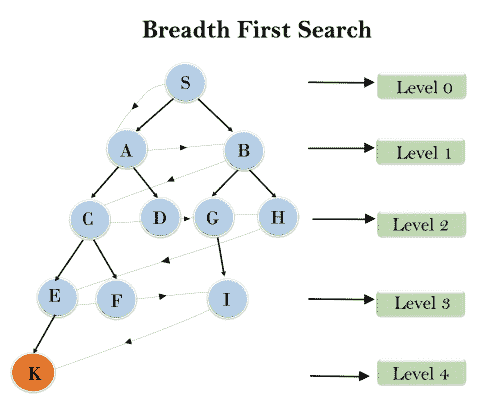
时间复杂度: BFS 算法的时间复杂度可以通过在 BFS 遍历到最浅 Node 的节点数得到。其中 d=最浅解的深度,b 是每个状态下的节点。
T(b)= 1+b2+b3+…+ b d = O (b d )
空间复杂度: BFS 算法的空间复杂度由前沿的内存大小给出,即 O(b d )。
完备性: BFS 是完备的,这意味着如果最浅的目标节点在某个有限的深度,那么 BFS 就会找到解。
最优性: 如果路径成本是节点深度的非递减函数,则 BFS 最优。
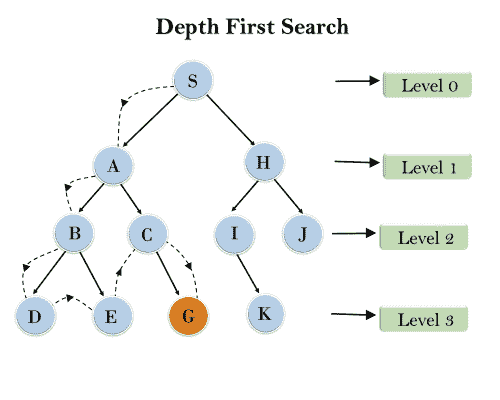
深度优先搜索
深度优先搜索是遍历树或图数据结构的递归算法。
它被称为深度优先搜索,因为它从根节点开始,在移动到下一个路径之前,沿着每个路径到达其最大深度节点。
DFS 使用堆栈数据结构来实现。
DFS 算法的过程类似于 BFS 算法。
注意:回溯是一种使用递归寻找所有可能解的算法技术。
优势:
DFS 需要非常少的内存,因为它只需要存储从根节点到当前节点的路径上的节点堆栈。
到达目标节点比 BFS 算法花费的时间少(如果它以正确的路径遍历)。
劣势:
许多州有可能会再次发生,而且无法保证找到解决方案。
DFS 算法进行深入的搜索,有时可能会进入无限循环。
示例:
在下面的搜索树中,我们显示了深度优先搜索的流程,它将遵循以下顺序:
根节点->左节点->右节点。
它将从根节点 S 开始搜索,遍历 A,然后 B,然后 D 和 E,遍历 E 后,由于 E 没有其他后继节点,仍然没有找到目标节点,它将回溯树。在回溯之后,它将遍历节点 C,然后遍历节点 G,这里它将在找到目标节点时终止。
完整性: DFS 搜索算法在有限状态空间内是完整的,因为它将扩展有限搜索树内的每个节点。
时间复杂度: DFS 的时间复杂度将相当于算法遍历的节点。它由下式给出:
T(n)= 1+n2+n3+…+ n m =O(n m )
其中,m=任何节点的最大深度,这可以比 d(最浅解深度) 大得多
空间复杂度: DFS 算法只需要存储从根节点开始的单条路径,因此 DFS 的空间复杂度相当于边缘集的大小,即为 O(bm) 。
最优: DFS 搜索算法是非最优的,因为它可能会产生大量的步骤或高成本来到达目标节点。
深度受限搜索算法:
深度受限搜索算法类似于具有预定限制的深度优先搜索。深度受限搜索可以解决深度优先搜索中无限路径的缺点。在该算法中,深度极限处的节点将被视为没有后续节点。
深度受限搜索可以在两种失败情况下终止:
标准故障值:表示问题没有任何解决方案。
截止故障值:它定义了在给定的深度限制内没有问题的解决方案。
优势:
深度受限搜索是内存高效的。
缺点:
深度受限搜索也有不完整的缺点。
如果问题有多个解决方案,这可能不是最佳方案。
示例:
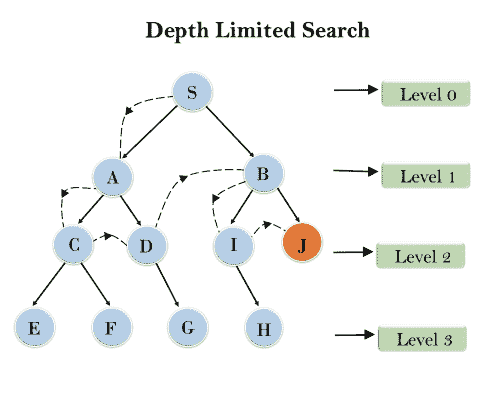
完备性: 如果解在深度极限以上,则 DLS 搜索算法完备。
时间复杂度: DLS 算法的时间复杂度为 O(b ℓ ) 。
空间复杂度: DLS 算法的空间复杂度为 O (bℓ) 。
最优: 深度受限搜索可以看作是 DFS 的特例,即使ℓ > d 也不是最优的。
均匀成本搜索算法:
均匀成本搜索是一种用于遍历加权树或图的搜索算法。当每条边的成本不同时,这种算法就开始发挥作用。均匀成本搜索的主要目标是找到一条到达累积成本最低的目标节点的路径。均匀成本搜索根据节点形成根节点的路径成本来扩展节点。它可以用来求解任何需要最优成本的图/树。优先级队列实现了一种均匀成本搜索算法。它给予最低的累积成本最大的优先权。如果所有边的路径代价相同,则均匀代价搜索等价于 BFS 算法。
优势:
均匀成本搜索是最优的,因为在每个状态下,成本最小的路径被选择。
缺点:
它不关心搜索涉及的步骤数,只关心路径开销。因此该算法可能陷入无限循环。
示例:
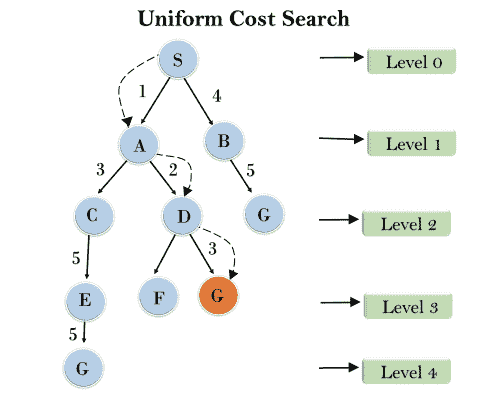
完整性:
均匀成本搜索是完整的,比如如果有解决方案,UCS 会找到它。
时间复杂度:
设 C* 为最优解的代价, ε 为每一步向目标节点靠拢。那么步数就是= C*/ε+1。这里我们取+1,从状态 0 开始,到 C*/ε结束。
因此,均匀成本搜索的最坏情况时间复杂度是O(b1+【C */ε】)/。
空间复杂度:
同样的逻辑也适用于空间复杂度,所以均匀成本搜索的最坏情况空间复杂度是O(b1+【C */ε】)。
最优:
均匀成本搜索总是最优的,因为它只选择路径成本最低的路径。
迭代深度优先搜索:
迭代深化算法是离散傅立叶变换和 BFS 算法的结合。这种搜索算法找出最佳深度极限,并通过逐渐增加极限直到找到目标来实现。
该算法在一定的“深度极限”内进行深度优先搜索,每次迭代后不断增加深度极限,直到找到目标节点。
这种搜索算法结合了广度优先搜索的快速搜索和深度优先搜索的内存效率的优点。
当搜索空间较大,目标节点深度未知时,迭代搜索算法是有用的无信息搜索。
优势:
它结合了 BFS 和 DFS 搜索算法在快速搜索和内存效率方面的优势。
缺点:
IDDFS 的主要缺点是它重复了前一阶段的所有工作。
示例:
遵循树结构显示的是迭代深化深度优先搜索。IDDFS 算法执行各种迭代,直到没有找到目标节点。算法执行的迭代如下所示:
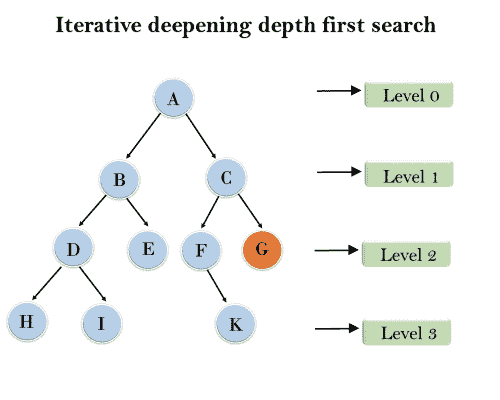
第 1 次迭代- > A
第 2 次迭代- > A、B、C
第 3 次迭代- > A、B、D、E、C、F、G
第 4 次迭代- > A、B、D、H、I、E、C、F、K、G
在第 4 次迭代中,算法会找到目标节点。
完整性:
如果分支因子是有限的,这个算法就是完整的。
时间复杂度:
假设 b 是分支因子,深度是 d,那么最坏的时间复杂度是 O(b d ) 。
空间复杂度:
IDDFS 的空间复杂度将为 O(bd) 。
最优:
如果路径成本是节点深度的非递减函数,则 IDDFS 算法是最优的。
双向搜索算法:
双向搜索算法运行两个同时进行的搜索,一个形成初始状态称为前向搜索,另一个来自目标节点称为后向搜索,以找到目标节点。双向搜索用两个小的子图代替一个单一的搜索图,其中一个从初始顶点开始搜索,另一个从目标顶点开始搜索。当这两幅图相交时,搜索停止。
双向搜索可以使用 BFS、DFS、DLS 等搜索技术。
优势:
双向搜索很快。
双向搜索需要较少的内存
缺点:
双向搜索树的实现是困难的。
在双向搜索中,要提前知道目标状态。
示例:
在下面的搜索树中,应用了双向搜索算法。该算法将一个图/树分成两个子图。它从节点 1 开始向前穿越,从目标节点 16 开始向后穿越。
该算法在两个搜索相遇的节点 9 处终止。
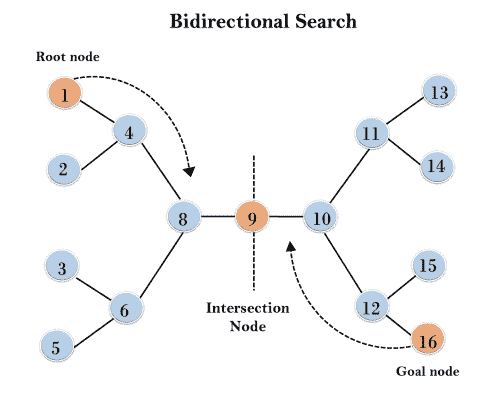
完整性: 如果我们在两个搜索中都使用 BFS,则双向搜索完成。
时间复杂度: 使用 BFS 双向搜索的时间复杂度为 O(b d ) 。
空间复杂度: 双向搜索的空间复杂度为 O(b d ) 。
最优: 双向搜索最优。
知情搜索
知情搜索算法使用领域知识。在有根据的搜索中,有问题信息可以指导搜索。有根据的搜索策略比无根据的搜索策略能更有效地找到解决方案。知情搜索也称为启发式搜索。
启发式是一种不一定能保证得到最佳解决方案,但能保证在合理的时间内找到好的解决方案的方法。
信息搜索可以解决许多用另一种方法无法解决的复杂问题。
知情搜索算法的一个例子是旅行推销员问题。
最佳优先搜索算法(贪婪搜索)
A*搜索算法
最佳优先搜索算法(贪婪搜索):
贪婪最佳优先搜索算法总是选择在那个时刻出现最好的路径。它是深度优先搜索和广度优先搜索算法的结合。它使用启发式函数和搜索。最佳优先搜索允许我们利用两种算法的优势。借助最佳优先搜索,在每一步,我们都可以选择最有希望的节点。在最佳优先搜索算法中,我们扩展最接近目标节点的节点,并通过启发式函数估计最接近的代价,即
|
wae,h(n)=从节点 n 到目标的估计成本。
贪婪最佳优先算法由优先级队列实现。
最佳优先搜索算法:
步骤 1: 将起始节点放入 OPEN 列表。
步骤 2: 如果打开列表为空,则停止并返回失败。
步骤 3: 从 h(n)值最低的 OPEN 列表中删除节点 n,并将其放入 CLOSED 列表中。
步骤 4: 展开节点 n,生成节点 n 的后继节点。
步骤 5: 检查节点 n 的各个后继节点,看是否有节点是目标节点。如果任何后续节点是目标节点,则返回成功并终止搜索,否则继续步骤 6。
步骤 6: 对于每个后继节点,算法检查评估函数 f(n),然后检查该节点是否已经在 OPEN 或 CLOSED 列表中。如果该节点不在两个列表中,则将其添加到打开列表中。
步骤 7: 返回第 2 步。
优点:
最佳优先搜索可以通过获得两种算法的优点在 BFS 和 DFS 之间切换。
该算法比 BFS 和 DFS 算法更有效。
缺点:
在最坏的情况下,它可以表现为非制导深度优先搜索。
它会像 DFS 一样陷入循环。
这个算法不是最优的。
示例:
考虑下面的搜索问题,我们将使用贪婪的最佳优先搜索来遍历它。在每次迭代中,使用评估函数 f(n)=h(n)扩展每个节点,如下表所示。
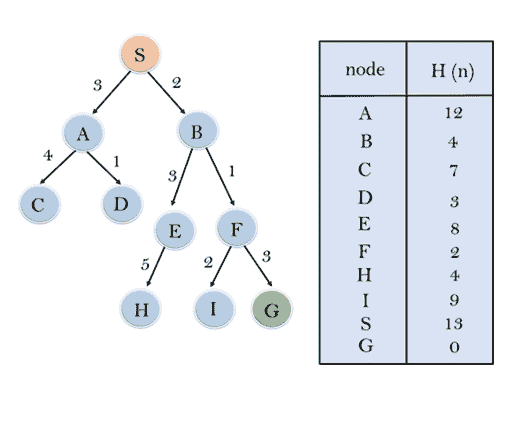
在这个搜索示例中,我们使用了两个列表,即打开和关闭列表。以下是遍历上述示例的迭代。
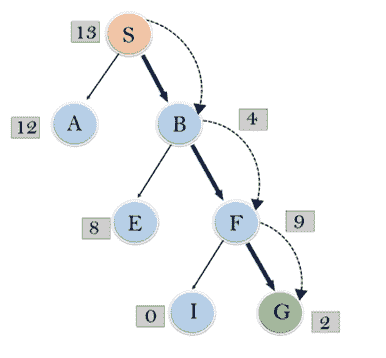
展开 S 的节点,放入 CLOSED 列表
初始化: 打开【A,B】,关闭【S】
迭代 1: 打开[A],关闭[S,B]
迭代 2: 打开【E,F,A】,关闭【S,B】
:打开【E,A】,关闭【S,B,F】
迭代 3: 打开【I,G,E,A】,关闭【S,B,F】
:打开【I,E,A】,关闭【S,B,F,G】
因此,最终的解决方案将是: S - > B - > F - > G
时间复杂度: 贪婪最佳第一次搜索的最坏情况时间复杂度为 O(b m )。
空间复杂度: 贪婪最佳第一搜索的最坏情况空间复杂度为 O(b m )。其中,m 是搜索空间的最大深度。
完成: 贪婪的最佳优先搜索也是不完全的,即使给定的状态空间是有限的。
最优: 贪婪最佳优先搜索算法不是最优的。
A*搜索算法:
A搜索是最常见的最佳优先搜索形式。它使用启发式函数 h(n)和代价从起始状态 g(n)到达节点 n。它结合了 UCS 和贪婪最佳优先搜索的特点,有效地解决了这个问题。A搜索算法使用启发式函数找到通过搜索空间的最短路径。这种搜索算法扩展较少的搜索树,更快地提供最优结果。A*算法除了用 g(n)+h(n)代替 g(n)之外,与 UCS 相似。
在 A*搜索算法中,我们使用搜索启发式以及到达节点的代价。因此,我们可以将两个成本合并如下,这个总和称为健身数。
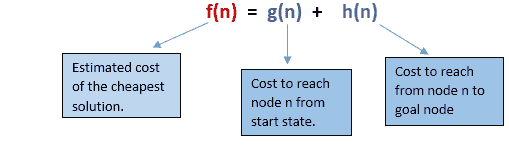
在搜索空间的每一点,只有那些 f(n)值最低的节点被展开,当找到目标节点时,算法终止。
A*搜索的算法:
步骤 1: 将起始节点放入 OPEN 列表中。
步骤 2: 检查 OPEN 列表是否为空,如果列表为空则返回失败并停止。
步骤 3: 从 OPEN 列表中选择评价函数值(g+h)最小的节点,如果节点 n 为目标节点则返回成功并停止,否则
步骤 4: 展开节点 n 并生成其所有后继节点,将 n 放入封闭列表。对于每个后继 n’,检查 n’是否已经在打开或关闭列表中,如果没有,则计算 n’的评估函数,并将其放入打开列表中。
步骤 5: 否则如果节点 n’已经处于 OPEN 和 CLOSED 状态,那么它应该被附加到反映最低 g(n’)值的后指针。
步骤 6: 返回第二步。
优点:
A*搜索算法是比其他搜索算法更好的算法。
A*搜索算法是最优且完整的。
这个算法可以解决非常复杂的问题。
缺点:
它并不总是产生最短路径,因为它主要基于启发式和近似。
A*搜索算法存在一些复杂性问题。
A*的主要缺点是内存需求,因为它将所有生成的节点都保存在内存中,因此对于各种大规模问题来说并不实用。
示例:
In this example, we will traverse the given graph using the A* algorithm. The heuristic value of all states is given in the below table so we will calculate the f(n) of each state using the formula f(n)= g(n) + h(n), where g(n) is the cost to reach any node from start state. Here we will use OPEN and CLOSED list. 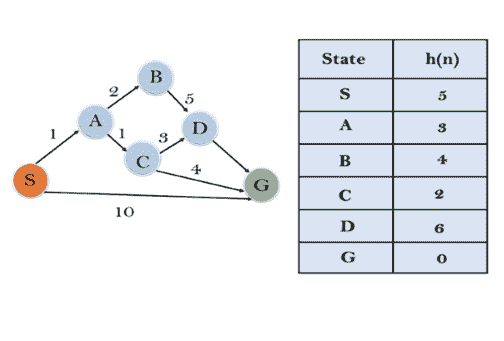
解决方案:
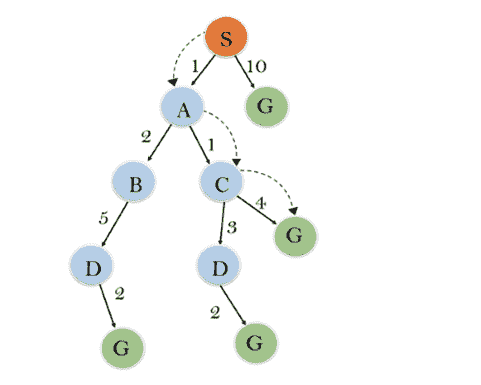
初始化: {(S,5)}
迭代 1: {(S - > A,4),(S - > G,10)}
迭代 2: {(S - > A - > C,4),(S - > A - > B,7),(S - > G,10)}
迭代 3: {(S - > A - > C - > G,6),(S - > A - > C - > D,11),(S - > A - > B,7),(S - > G,10)}
迭代 4 将给出最终结果,因为 S - > A - > C - > G 它提供了成本为 6 的最优路径。
需要记住的点:
A*算法返回最先出现的路径,它不搜索所有剩余的路径。
A*算法的效率取决于启发式的质量。
A*算法扩展所有满足条件 f(n) 的节点
完成: A*算法完成只要:
分支因子是有限的。
每次行动的成本是固定的。
最优: A*搜索算法在满足以下两个条件时为最优:
容许: 最优性要求的第一个条件是 h(n)应该是 A*树搜索的容许启发式。可接受的启发本质上是乐观的。
一致性: 第二个要求的条件是一致性,仅适用于 A*图形搜索。
如果启发式函数是可接受的,那么 A*树搜索将总是找到成本最小的路径。
时间复杂度: a*搜索算法的时间复杂度取决于启发式函数,展开的节点数与解 d 的深度成指数关系,因此时间复杂度为 O(b^d),其中 b 为分支因子。
空间复杂度: a*搜索算法的空间复杂度为 O(b^d)
 wechat
wechat alipay
alipay




