多项式朴素贝叶斯(Multinomial Naive Bayes)算法,用于文本分类(这个领域中数据往往以词向量表示,尽管在实践中 tf-idf向量在预测时表现良好)的两大经典朴素贝叶斯算法之一。分布参数由每类的向量决定, 式中 n 是特征的数量(对于文本分类,是词汇量的大小)是样本中属于类 y 中特征i概率 。
#GaussianNB differ from MultinomialNB in these two method: # _calculate_feature_prob, _get_xj_prob classGaussianNB(MultinomialNB): """ GaussianNB inherit from MultinomialNB,so it has self.alpha and self.fit() use alpha to calculate class_prior However,GaussianNB should calculate class_prior without alpha. Anyway,it make no big different """ #calculate mean(mu) and standard deviation(sigma) of the given feature def_calculate_feature_prob(self,feature): mu = np.mean(feature) sigma = np.std(feature) return (mu,sigma)
#the probability density for the Gaussian distribution def_prob_gaussian(self,mu,sigma,x): return ( 1.0/(sigma * np.sqrt(2 * np.pi)) * np.exp( - (x - mu)**2 / (2 * sigma**2)) )
#given mu and sigma , return Gaussian distribution probability for target_value def_get_xj_prob(self,mu_sigma,target_value): return self._prob_gaussian(mu_sigma[0],mu_sigma[1],target_value)

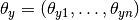 向量决定, 式中 n 是特征的数量(对于文本分类,是词汇量的大小)
向量决定, 式中 n 是特征的数量(对于文本分类,是词汇量的大小)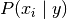 。
。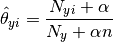
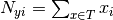 是训练集T中特征 i 在类 y 中出现的次数,
是训练集T中特征 i 在类 y 中出现的次数,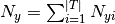 是类y中出现所有特征的计数总和。
是类y中出现所有特征的计数总和。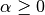 应用于在学习样本中没有出现的特征,以防在将来的计算中出现0概率输出。 把
应用于在学习样本中没有出现的特征,以防在将来的计算中出现0概率输出。 把 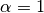 被称为拉普拉斯平滑(Lapalce smoothing),而
被称为拉普拉斯平滑(Lapalce smoothing),而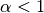 被称为利德斯通(Lidstone smoothing)。
被称为利德斯通(Lidstone smoothing)。 wechat
wechat alipay
alipay









