
Flink状态管理与Checkpoint机制(一)
何为状态?
计算任务的结果不仅仅依赖于输入,还依赖于它的当前状态,其实大多数的计算都是有状态的计算。比如wordcount,给一些word,其计算它的count,这是一个很常见的业务场景。count做为输出,在计算的过程中要不断的把输入累加到count上去,那么count就是一个state。
在批处理过程中,数据是划分为块分片去完成的,然后每一个Task去处理一个分片。当分片执行完成后,把输出聚合起来就是最终的结果。在这个过程当中,对于state的需求还是比较小的。
在流处理过程中,对State有非常高的要求,因为在流系统中输入是一个无限制的流,会持续运行从不间断。在这个过程当中,就需要将状态数据很好的管理起来
检查点checkpoint与Barrier
checkpoint【可以理解为checkpoint是把state数据持久化存储了】,则表示Flink job在一个特定时刻的一份全局状态快照,即包含了所有的task/operator的状态。
Checkpoint是Flink实现容错机制最核心的功能,它能根据配置周期性地基于Stream中各个Operator/Task的状态来生成快照,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。
Flink分布式快照算法Asynchronous Barrier Snapshots算法借鉴了经典的Chandy-Lamport算法的主要思想,同时做了一些改进。Lightweight Asynchronous Snapshots for Distributed Dataflows
Chandy-Lamport算法
分布式系统是一个包含有限进程和有限消息通道的系统,这些进程和通道可以用一个有向图描述,其中节点表示进程,边表示通道。如下图所示:p、q分别是进程,c->c’则是消息通道,分布式系统快照是了保存分布式系统的state。分布式系统State是由进程状态和通道状态组成的。

Event:分布式系统中发生的一个事件,在类似于Flink这样的分布式计算系统中从Source输入的新消息相当于一个事件
进程状态:包含一个初始状态(initial state),和持续发生的若干Events。初始状态可以理解为Flink中刚启动的计算节点,计算节点每处理一条Event,就转换到一个新的状态。
通道状态:我们用在通道上传输的消息(Event)来描述一个通道的状态。
进程p启动这个算法,记录自身状态,并发出Marker。随着Marker不断的沿着分布式系统的相连通道逐渐传输到所有的进程,所有的进程都会执行算法以记录自身状态和入射通道的状态,**待到所有进程执行完该算法,一个分布式Snapshot就完成了记录。**Marker相当于是一个信使,它随着消息流流经所有的进程,通知每个进程记录自身状态。且Marker对整个分布式系统的计算过程没有任何影响。只要保证Marker能在有限时间内通过通道传输到进程,每个进程能够在有限时间内完成自身状态的记录,这个算法就能在有限的时间内执行完成。
Flink分布式快照算法ABS
在ABS算法中用Barrier代替了C-L算法中的Marker。
Barrier周期性的被注入到所有的Source中,Source节点看到Barrier之后,就会立即记录自己的状态,然后将Barrier发送到Transformation Operator。
当Operator从某个input channel收到Barrier之后,会立即Block住这条通道,直到收到所有的input channel的Barrier,此时Operator会记录自身状态,并向自己所有的output channel广播Barrier。
Sink接受Barrier的操作流程与Transformation Operator一样。当所有的Barrier都到达Sink之后,并且所有的Sink也完成了Checkpoint,这一轮Snapshot就完成了。

上述算法中Block Input实际上是有负面效果的,一旦某个input channel发生延迟,Barrier迟迟未到,就会导致Operator上的其他通道全部堵塞,导致系统吞吐下降。但有个一好处是可以实现Exactly Once。
一轮快照整个执行流程如下所示:

Checkpoint统一由JobManager发起,中间涉及到JobManager和TaskManager的交互,一轮快照可以分为4个阶段:
JobManager checkpoint的发起
全局协调控制的核心抽象是CheckpointCoordinator,发起时的checkpoint被抽象成PendingCheckpoint,向所有的Source节点发送barrier。图中第一步
barrier的传递
当operator收到所有input channel的barrier之后,将barrier传递给下一个operator/task。图中第二步
operator/task的checkpoint
当operator/task收到所有input channels的barrier,本地计算完成后,进行状态持久化。图中第三步
ack消息回传
当TaskManager完成本地备份之后,并将数据的地址以及快照句柄等通过akka以ack消息的形式发送给CheckpointCoordinator,由其负责维护这一轮快照的全局状态视图。当CheckpointCoordinator 收到所有的ack消息后,此时checkpoint的状态由PendingCheckpoint变为 CompletedCheckpoint。此时一次checkpoint完成。图中剩余步骤
单流

每个Barrier携带着快照的ID,快照记录着ID,并将其放在快照数据的前面。
单流时两个Barrier之间的数据,存储在相应的barrierID中,例如barrier n-1和n之间的数据存储在Barrier n中。
多流

比如此operator有两个输入流,当收到第一个流的barrier n时,下一个流的barrier n-1还有数据流入,此时会先临时搁置此流的数据,将数据放入缓存buffer中,即1 2 3临时存储起来。待所有输入通道都收到了barrier n时,此时所有之前的数据都是barrier n-1的数据。然后该operator会释放buffer中的数据,继续处理。
虽然该方法有效的实现了Exactly Once,但是一旦某个input channel发生延迟,Barrier迟迟未到,这会导致Transformation Operator上的其它通道全部堵塞,系统吞吐大幅下降。Flink提供了选项,可以关闭Exactly once并仅保留at least once。
checkpoint的存储
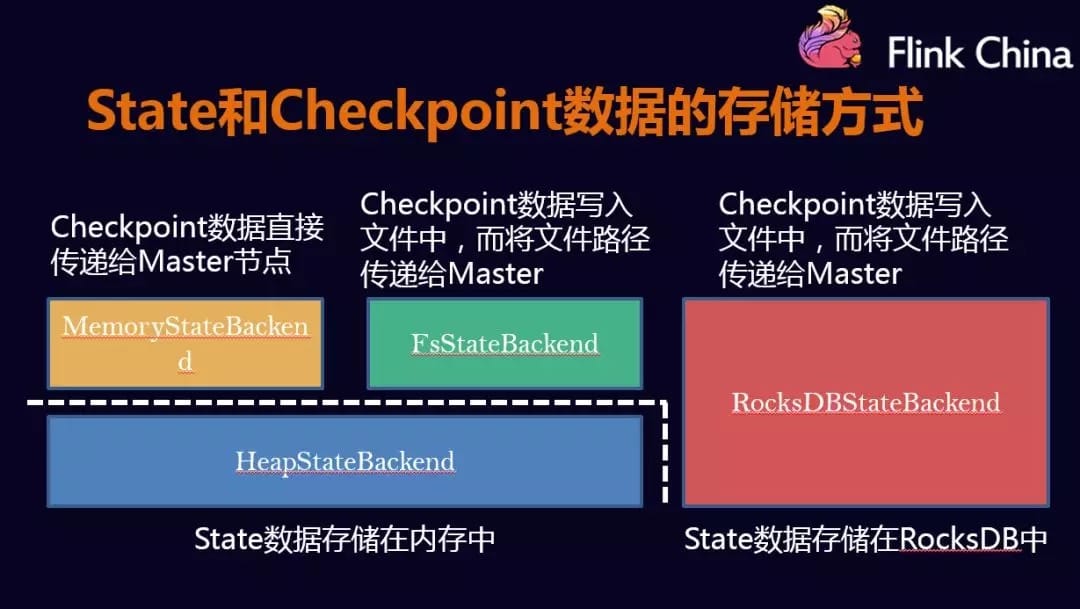
用户可以根据自己的需求选择,如果数据量较小,可以存放到MemoryStateBackend和FsStateBackend中,如果数据量较大,可以放到RockDB中。
HeapStateBackend

MemoryStateBackend 和 FsStateBackend 都是存储在内存中,被保存在一个由多层Java Map嵌套而成的数据结构中,默认不超过5M。优点:速度快,缺点:容量小
RocksDBStateBackend
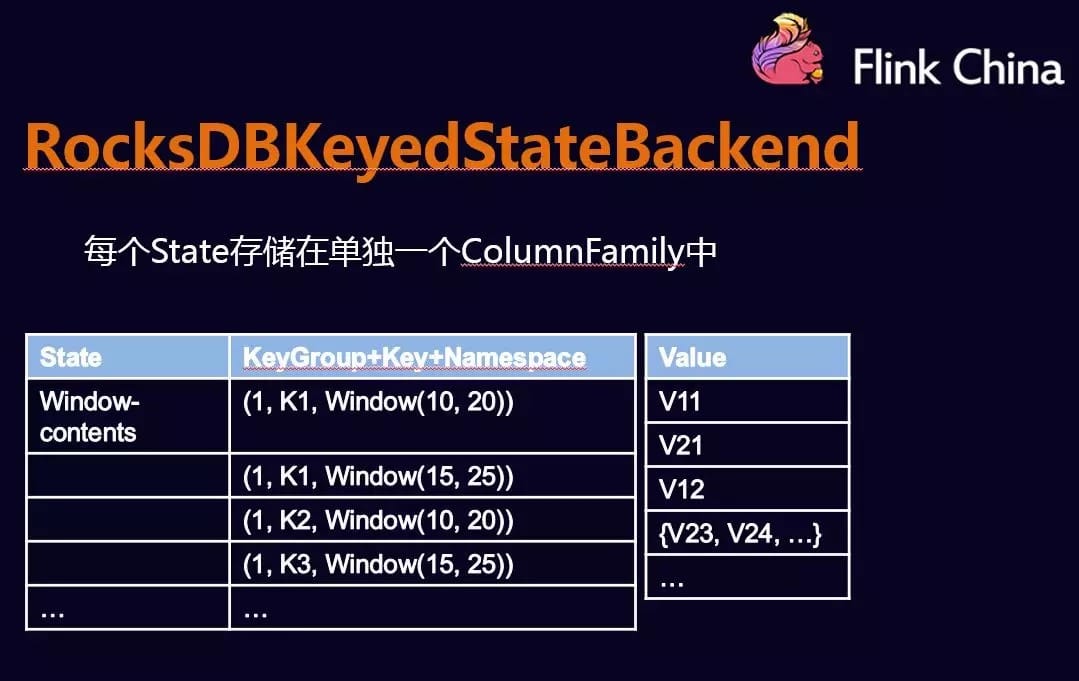
RockDBKeyedStateBackend 每个State单独存储在一个ColumnFamily中。会在本地文件系统中维护状态,state会直接写入本地rocksdb中。同时RocksDB需要配置一个远端的filesystem。uri(一般是HDFS),在做checkpoint的时候,会把本地的数据直接复制到filesystem中。fail over的时候从filesystem中恢复到本地。RocksDB克服了state受内存限制的缺点,同时又能够持久化到远端文件系统中,比较适合在生产中使用。
RocksDB全量快照
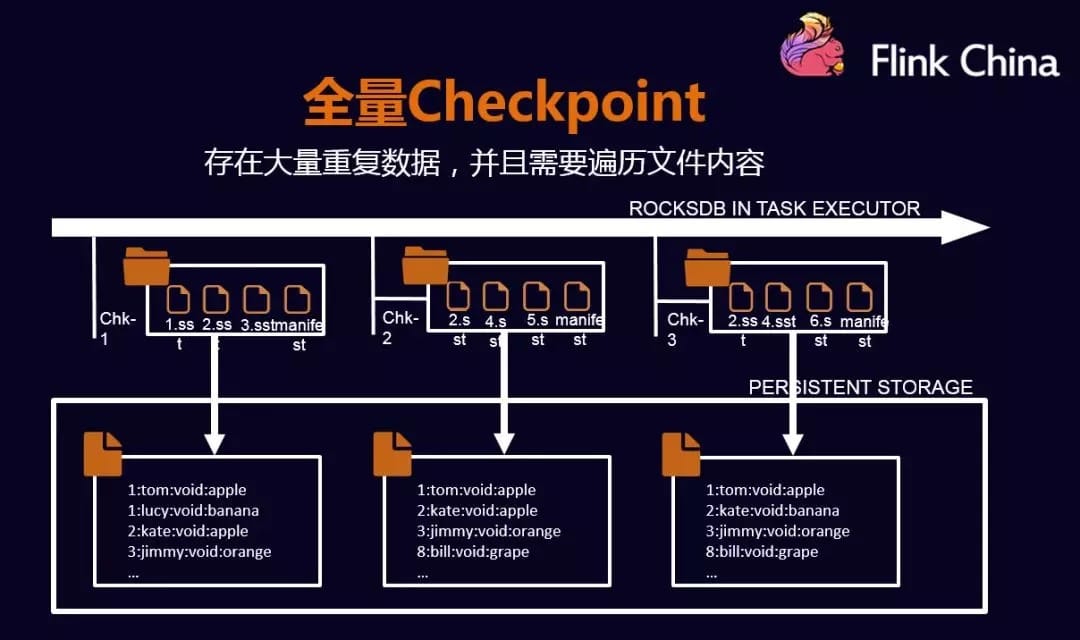
全量checkpoint会在每个节点做备份数据时,需要将数据都遍历一遍,然后写入到外部存储中,这种情况会影响备份性能。
RocksDB 自身的snapshot 全量写出,主要步骤如下:
拿到RocksDB 自身的 snapshot 对象
通过 CheckpointStreamFactory 拿到 CheckpointStateOutputStream 作为快照写出流
分别将快照的 meta 信息和数据写到 2 对应的输出流中
拿到 2 输出流的句柄,获取状态offset,将 k-v 数据读取到RocksDB中,这里要注意的是快照时留下的 meta 起始标志位【标志一个新的 state 起始或者一个 keyGroup 结束】,快照恢复时需要复原.
将 RocksDB 的快照对象及一些辅助资源释放

RocksDB增量快照
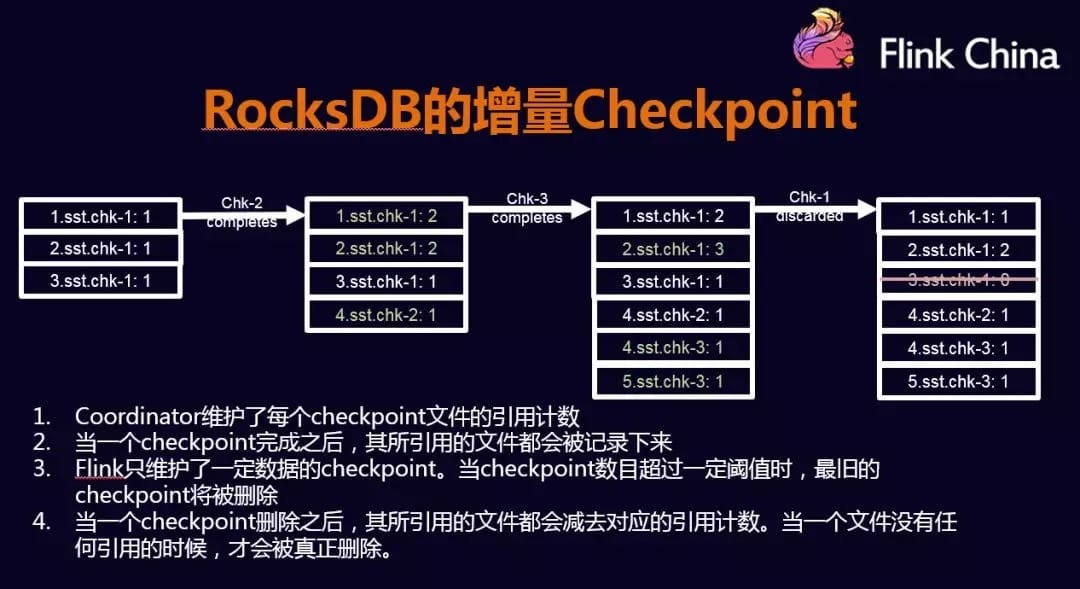
RocksDB 的数据会更新到内存,当内存满时,会写入到磁盘中。增量的机制会将新产生的文件copy持久化中,而之前产生的文件就不需要COPY到持久化中了。这种方式减少了COPY的数据量,并提高性能。
 wechat
wechat alipay
alipay









