误差反向传播 | 字数总计: 3.5k | 阅读时长: 12分钟 | 阅读量: |
反向传播(Backpropagation) 反向传播(Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法对网络中所有权重计算损失函数(Loss Function)的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。反向传播要求有对每个输入值想得到的已知输出,来计算损失函数梯度。因此,它通常被认为是一种监督式学习方法,虽然它也用在一些无监督网络(如自动编码器Autoencoder)中。它是多层前馈网络的Delta规则(Delta Rule)的推广,可以用链式法则对每层迭代计算梯度。反向传播要求人工神经元(Artificial Neuron)(或“节点”)的激励函数可微。
反向传播模型,是一种用于前向多层的反向传播学习算法。之所以称它是一种学习方法,是因为用它可以对组成前向多层网络的各人工神经元之间的连接权值进行不断的修改,从而使该前向多层网络能够将输入它的信息变换成所期望的输出信息。之所以将其称作为反向学习算法,是因为在修改各人工神经元的连接权值时,所依据的是该网络的实际输出与其期望的输出之差,将这一差值反向一层一层的向回传播,来决定连接权值的修改。
B-P算法的网络结构是一个前向多层网络,其基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。正向传播时,输入样本从输入层传入,经隐含层逐层处理后,传向输出层。若输出层的实际输出与期望输出不符,则转向误差的反向传播阶段。误差的反向传播是将输出误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。这种信号正向传播与误差反向传播的各层权值调整过程,是周而复始地进行。权值不断调整过程,也就是网络的学习训练过程。此过程一直进行到网络输出的误差减少到可以接受的程度,或进行到预先设定的学习次数为止。
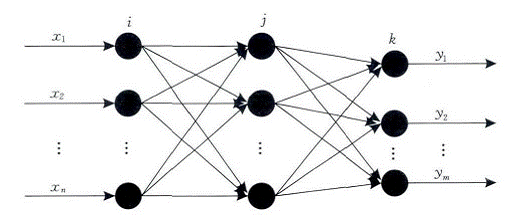
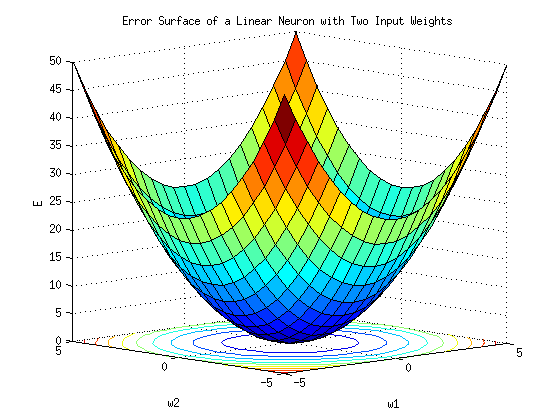
BP网络的拓扑结构包括输入层、隐层和输出层,它能够在事先不知道输入输出具体数学表达式的情况下,通过学习来存储这种复杂的映射关系.其网络中参数的学习通常采用反向传播的策略,借助最速梯度信息来寻找使网络误差最小化的参数组合.常见的3层BP网络模型如图所示
任何监督式学习算法的目标是找到一个能把一组输入最好地映射到其正确的输出的函数。例如一个简单的分类任务,其中输入是动物的图像,正确的输出将是动物的名称。一些输入和输出模式可以很容易地通过单层神经网络(如感知器)学习。但是这些单层的感知机不能学习一些比较简单的模式,例如那些非线性可分的模式。例如,人可以通过识别动物的图像的某些特征进行分类,例如肢的数目,皮肤的纹理(无论是毛皮,羽毛,鳞片等),该动物的体型,以及种种其他特征。但是,单层神经网络必须仅仅使用图像中的像素的强度来学习一个输出一个标签函数。因为它被限制为仅具有一个层,所以没有办法从输入中学习到任何抽象特征。多层的网络克服了这一限制,因为它可以创建内部表示,并在每一层学习不同的特征。第一层可能负责从图像的单个像素的输入学习线条的走向。第二层可能就会结合第一层所学并学习识别简单形状(如圆形)。每升高一层就学习越来越多的抽象特征,如上文提到的用来图像分类。每一层都是从它下方的层中找到模式,就是这种能力创建了独立于为多层网络提供能量的外界输入的内部表达形式。 反向传播算法的发展的目标和动机是找到一种训练的多层神经网络的方法,于是它可以学习合适的内部表达来让它学习任意的输入到输出的映射。
反向传播算法(BP算法)主要由两个阶段:激励传播与权重更新. 每次迭代中的传播环节包含两步:
对于每个突触上的权重,按照以下步骤进行更新:
第1和第2阶段可以反复循环迭代,直到网络的对输入的响应达到满意的预定的目标范围为止。
三层网络算法(只有一个隐藏层):
这个算法的名称意味着误差会从输出结点反向传播到输入结点。严格地讲,反向传播算法对网络的可修改权值计算了网络误差的梯度。[2] 这个梯度会在简单随机梯度下降法中经常用来求最小化误差的权重。通常“反向传播”这个词使用更一般的含义,用来指涵盖了计算梯度以及在随机梯度下降法中使用的整个过程。在适用反向传播算法的网络中,它通常可以快速收敛到令人满意的极小值。
由于反向传播使用梯度下降法,需要计算平方误差函数对网络权重的导数。假设对于一个输出神经元,平方误差函数为:
其中E 为平方误差,t 为训练样本的目标输出,y 为输出神经元的实际输出。加入系数
通向一个神经元的输入
激活函数
其导数的形式很好:
求误差的导数 计算误差对权重
在右边的最后一项中,只有加权和
神经元j 的输出对其输入的导数就是激活函数的偏导数(这里假定使用逻辑函数):
这就是为什么反向传播需要的激活函数是可微的。如果神经元在输出层中,因为此时
所以第一项可以直接算出。但如果j 是网络中任一内层,求E关于
考虑E为接受来自神经元j的输入的所有神经元
并关于
因此,若已知所有关于下一层(更接近输出神经元的一层)的输出把它们放在一起:
其中:
要使用梯度下降法更新
之所以要乘以-1 是因为要更新误差函数极小值而不是极大值的方向。对于单层网络,这个表达式变为Delta规则。
应用示例 import randomimport mathclass NeuralNetwork : LEARNING_RATE = 0.5 def __init__ (self, num_inputs, num_hidden, num_outputs, hidden_layer_weights = None , hidden_layer_bias = None , output_layer_weights = None , output_layer_bias = None ): self.num_inputs = num_inputs self.hidden_layer = NeuronLayer(num_hidden, hidden_layer_bias) self.output_layer = NeuronLayer(num_outputs, output_layer_bias) self.init_weights_from_inputs_to_hidden_layer_neurons(hidden_layer_weights) self.init_weights_from_hidden_layer_neurons_to_output_layer_neurons(output_layer_weights) def init_weights_from_inputs_to_hidden_layer_neurons (self, hidden_layer_weights ): weight_num = 0 for h in range (len (self.hidden_layer.neurons)): for i in range (self.num_inputs): if not hidden_layer_weights: self.hidden_layer.neurons[h].weights.append(random.random()) else : self.hidden_layer.neurons[h].weights.append(hidden_layer_weights[weight_num]) weight_num += 1 def init_weights_from_hidden_layer_neurons_to_output_layer_neurons (self, output_layer_weights ): weight_num = 0 for o in range (len (self.output_layer.neurons)): for h in range (len (self.hidden_layer.neurons)): if not output_layer_weights: self.output_layer.neurons[o].weights.append(random.random()) else : self.output_layer.neurons[o].weights.append(output_layer_weights[weight_num]) weight_num += 1 def inspect (self ): print ('------' ) print ('* Inputs: {}' .format (self.num_inputs)) print ('------' ) print ('Hidden Layer' ) self.hidden_layer.inspect() print ('------' ) print ('* Output Layer' ) self.output_layer.inspect() print ('------' ) def feed_forward (self, inputs ): hidden_layer_outputs = self.hidden_layer.feed_forward(inputs) return self.output_layer.feed_forward(hidden_layer_outputs) def train (self, training_inputs, training_outputs ): self.feed_forward(training_inputs) pd_errors_wrt_output_neuron_total_net_input = [0 ] * len (self.output_layer.neurons) for o in range (len (self.output_layer.neurons)): pd_errors_wrt_output_neuron_total_net_input[o] = self.output_layer.neurons[o].calculate_pd_error_wrt_total_net_input(training_outputs[o]) pd_errors_wrt_hidden_neuron_total_net_input = [0 ] * len (self.hidden_layer.neurons) for h in range (len (self.hidden_layer.neurons)): d_error_wrt_hidden_neuron_output = 0 for o in range (len (self.output_layer.neurons)): d_error_wrt_hidden_neuron_output += pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].weights[h] pd_errors_wrt_hidden_neuron_total_net_input[h] = d_error_wrt_hidden_neuron_output * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_input() for o in range (len (self.output_layer.neurons)): for w_ho in range (len (self.output_layer.neurons[o].weights)): pd_error_wrt_weight = pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].calculate_pd_total_net_input_wrt_weight(w_ho) self.output_layer.neurons[o].weights[w_ho] -= self.LEARNING_RATE * pd_error_wrt_weight for h in range (len (self.hidden_layer.neurons)): for w_ih in range (len (self.hidden_layer.neurons[h].weights)): pd_error_wrt_weight = pd_errors_wrt_hidden_neuron_total_net_input[h] * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_weight(w_ih) self.hidden_layer.neurons[h].weights[w_ih] -= self.LEARNING_RATE * pd_error_wrt_weight def calculate_total_error (self, training_sets ): total_error = 0 for t in range (len (training_sets)): training_inputs, training_outputs = training_sets[t] self.feed_forward(training_inputs) for o in range (len (training_outputs)): total_error += self.output_layer.neurons[o].calculate_error(training_outputs[o]) return total_error class NeuronLayer : def __init__ (self, num_neurons, bias ): self.bias = bias if bias else random.random() self.neurons = [] for i in range (num_neurons): self.neurons.append(Neuron(self.bias)) def inspect (self ): print ('Neurons:' , len (self.neurons)) for n in range (len (self.neurons)): print (' Neuron' , n) for w in range (len (self.neurons[n].weights)): print (' Weight:' , self.neurons[n].weights[w]) print (' Bias:' , self.bias) def feed_forward (self, inputs ): outputs = [] for neuron in self.neurons: outputs.append(neuron.calculate_output(inputs)) return outputs def get_outputs (self ): outputs = [] for neuron in self.neurons: outputs.append(neuron.output) return outputs class Neuron : def __init__ (self, bias ): self.bias = bias self.weights = [] def calculate_output (self, inputs ): self.inputs = inputs self.output = self.squash(self.calculate_total_net_input()) return self.output def calculate_total_net_input (self ): total = 0 for i in range (len (self.inputs)): total += self.inputs[i] * self.weights[i] return total + self.bias def squash (self, total_net_input ): return 1 / (1 + math.exp(-total_net_input)) def calculate_pd_error_wrt_total_net_input (self, target_output ): return self.calculate_pd_error_wrt_output(target_output) * self.calculate_pd_total_net_input_wrt_input(); def calculate_error (self, target_output ): return 0.5 * (target_output - self.output) ** 2 def calculate_pd_error_wrt_output (self, target_output ): return -(target_output - self.output) def calculate_pd_total_net_input_wrt_input (self ): return self.output * (1 - self.output) def calculate_pd_total_net_input_wrt_weight (self, index ): return self.inputs[index] nn = NeuralNetwork(2 , 2 , 2 , hidden_layer_weights=[0.15 , 0.2 , 0.25 , 0.3 ], hidden_layer_bias=0.35 , output_layer_weights=[0.4 , 0.45 , 0.5 , 0.55 ], output_layer_bias=0.6 ) for i in range (10000 ): nn.train([0.05 , 0.1 ], [0.01 , 0.09 ]) print (i, round (nn.calculate_total_error([[[0.05 , 0.1 ], [0.01 , 0.09 ]]]), 9 ))
原文:https://github.com/KeKe-Li/tutorial

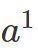 。
。 计算
计算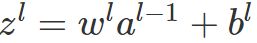 和
和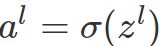 。
。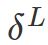 :计算向量
:计算向量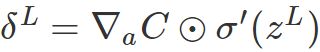 。
。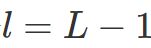 ,
,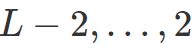 计算
计算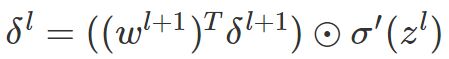
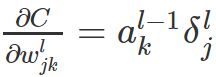 和
和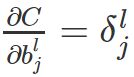

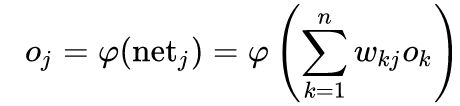
 是之前神经元的输出
是之前神经元的输出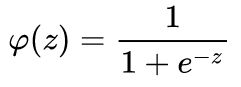
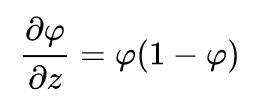
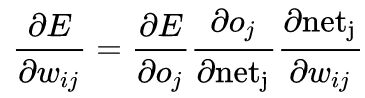
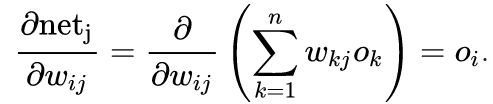
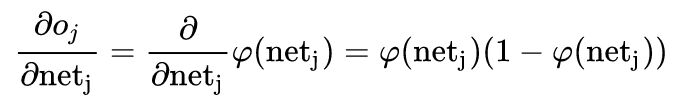
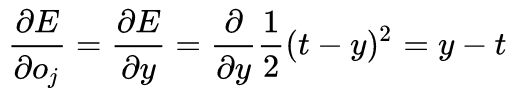
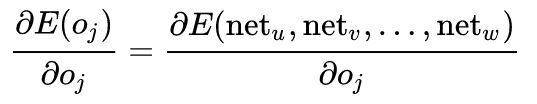
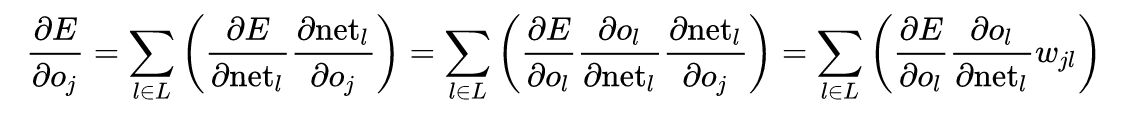
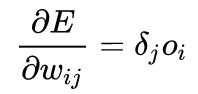
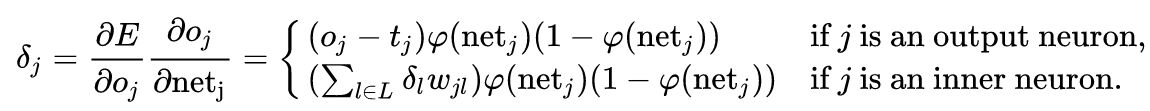
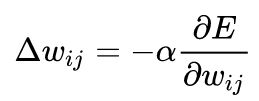
 wechat
wechat alipay
alipay







